缘起公司因为受够了无端的弱密码爆破而断开了所有服务对外的 NAT/端口映射,所有的服务都只能通过 VPN 访问了。为了降低管理上的时间成本,最近自己给自己找了个需求:将公司 ecology-9 OA 内登记的所有员工配置同步到新购置的 atrust 零信任设备,以便新员工入职自动开启 atrust VPN 权限,员工离职后也能及时收回内网的访问权限。
我们公司是一个对微软域套件,甚至微软操作系统都依赖不重的公司,对 AD 域、LDAP 等技术感冒不了一点,现在没有在使用,以后也断然不会使用。索性同步用户这种事就利用这些内网服务的 Open API 配合消息队列+微服务去完成吧。
本文章是“先进摸鱼学”系列文章中的第一篇,实际上我暂时没有确定具体的实践架构如何,“消息队列+微服务“甚至是”数据中台“这种更规范的模式或许不能因地制宜。根据我现在对系统结构和功能的理解,或许最合适的方案是:
反向同步端(OA)【轮询OA用户列表 ->全量读取 -> 数据清洗(仅保留在职真实员工) -> 数据库落盘】
正向同步端(atrust)【轮询设备端用户列表 -> 全量读取 -> 与数据库比对 -> 配置设备端用户列表及权限】
1、开通人力资源 RESTful API 访问权限
有两种方式可以获取访问权限,一种是平时开发最常见的 token+appid,另一种是 IP 地址白名单。我甚至觉得官方是有意避免用户使用 token+appid 进行开发的。因为在 ecology 中居然没有提供现有的配置业务来实现该功能,该功能完全是通过在数据库中执行 SQL 来完成的。对于生产环境来说,这种对业务不透明的修改是不能接受的。
所以我们使用最简单,也是最安全的 IP 白名单方式来实现授权:
编辑两个 HrmService 人力资源模块的配置文件,加入你的用户同步业务服务器和开发机的 IP 地址
# 文件一
\WEAVER\ecology\WEB-INF\prop\HrmOutInterfaceIP.properties
#isopen IP范围限制是否开启,1:开启 0:关闭
#调用人力资源外部接口的IP范围,多个中间请用逗号隔开
isopen=1
ipaddress=127.0.0.1,192.168.4.129,192.168.3.19
# 文件二
WEAVER\ecology\WEB-INF\prop\HrmWebserviceIP.properties
#调用人力资源webservice接口的ip范围,多个中间请用逗号隔开
ipaddress=127.0.0.1无需重启 ecology 中断业务,现在服务器已经可以接受来自用户同步业务服务器和开发机的 API 访问。
2、企业及员工信息架构
逻辑上,OA 的员工是以这种结构进行组织的:
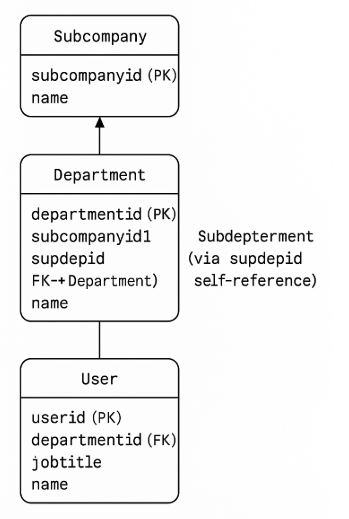
分部(subcompany)下设部门
部门中含有 subcompanyid1 字段关联到对应的分部
如果部门有自己的父部门,则通过 supdepid 字段进行自引用(如果为顶级部门则 supdepid 值为 0)
部门下有员工,使用 departmentid 字段关联到对应的部门,也使用 jobtitle 字段关联到员工自己的岗位综合所有的信息,可以为每个员工得到这样的路径:
/SubcompanyName/DepartmentA/SubDepartmentB/UserName例子:
/北京分部/技术部/前端组/张三
3、读取企业及员工信息
具体接口说明可参考泛微 E9 产品官方文档
https://e-cloudstore.com/doc.html?appId=c373a4b01fb74d098b62e2b969081d2d
实现这些接口的分页获取后,就可以对所有的信息进行链接整合了。我使用 node.js 进行开发,这里使用 Map 创建元素之间的映射,取数据时直接获取每对映射关系即可:
// /src/userInfoProcessor.js
const { getDepartments, getJobtitles, getSubcompanies, getUsers } = require('./api');
const { fetchAllSerial } = require('./utils/paginateFetch');
module.exports = async function processUserInfo() {
try {
const subcompanies = await fetchAllSerial(getSubcompanies);
const departments = await fetchAllSerial(getDepartments);
const jobtitles = await fetchAllSerial(getJobtitles);
const users = await fetchAllSerial(getUsers);
// 分部 (id、分部名称)
const subcompanyMap = Object.fromEntries(subcompanies.map(s => [s.id, s.subcompanyname]));
// 部门 (id、部门名称、所属上级部门id(为0时说明该部门为顶级部门))
const departmentMap = Object.fromEntries(departments.map(d => [d.id, { name: d.departmentname, supdepid: d.supdepid }]));
// 岗位 (id、岗位名称)
const jobMap = Object.fromEntries(jobtitles.map(j => [j.id, j.jobtitlename]));
// 用户 (id、姓名)
const userMap = Object.fromEntries(users.map(u => [u.id, u.lastname]));
const usersInfo = users.map(user => {
const departmentsArray = [];
let currentDepId = user.departmentid;
while (currentDepId !== undefined && currentDepId !== null && currentDepId !== 0) {
const currentDep = departmentMap[currentDepId];
if (currentDep) {
departmentsArray.unshift(currentDep.name);
currentDepId = currentDep.supdepid;
} else {
break;
}
}
const subcompanyName = subcompanyMap[user.subcompanyid1] || '未知分部';
departmentsArray.unshift(subcompanyName);
return {
id: user.id,
loginid: user.loginid,
name: user.lastname,
jobtitle: jobMap[user.jobtitle] || '',
manager: userMap[user.managerid] || '',
department: departmentsArray.length > 0 ? departmentsArray : ['']
};
});
return usersInfo;
} catch (error) {
console.error('处理用户信息时出错:', error);
throw error;
}
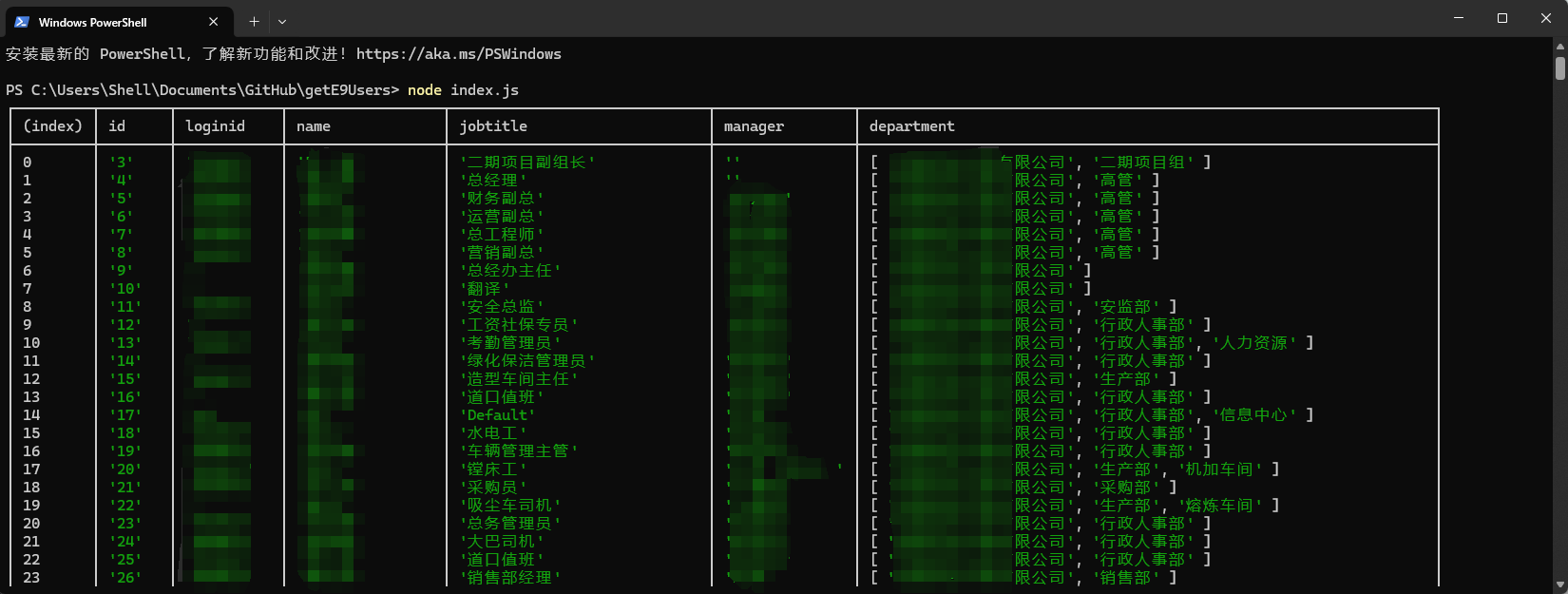
}调用该模块时,可以得到这样的输出:
// index.js
const processUserInfo = require('./src/userInfoProcessor');
(async () => {
try {
const usersInfo = await processUserInfo();
console.table(usersInfo);
} catch (error) {
console.error('执行过程中出错:', error);
}
})();
获取到的用户有许多字段,取出自己感兴趣的字段将其落盘存储即可。